Virtual Machine (Reversing x86)
To understand the whole process of a virtual machine we will be solving the following crackme created by: Towel.
https://crackmes.one/crackme/605443e333c5d42c3d016f59
Challenge: KataVM Level 1 Author: Towel towel@protonmail.com, @0xTowel Year: 2021 Info: A small challenge with a virtualized function. It is not designed to be overly difficult. Instead, it is designed to give you something simple to practice on. No fancy dynamic obfuscations or static analysis protections – just the VM. There is no flag, just working input and non-working input.
Goal: Your task is to find input that gives you the success message.
Before starting the writeup you need to know that we will be using the following tools:
- IDA (Pro 9.0) with notepad (recomendable)
- IDE for Python
Simple tools for an hard challenge :)
Starting with the main function, we found a if-conditional statement that checks a function:
__int64 __fastcall main(__int64 a1, char **a2, char **a3)
{
if ( vm_run() )
{
puts("\n[!] Invalid. Try harder.");
}
else
{
puts("\n[+] Correct!");
do
v3 = getc(stdin);
while ( v3 != -1 && v3 != 10 );
}
return 0LL;
}I have renamed the function before, so the finallity is to obtain a false return in vm_run(), with the address: 0x4012D0. I will try to avoid the pseudo-C and focus on pure assembly, so it is recomendable to know the basics concepts or arch x86-64 and bit-level operations.
Thus, here is our new friend for the next hours/days:

Before starting the hard reversing, we have to know how works or the basic structure of tha Virtual Machine inside the binaries, I have done this useful image that describes precisely the working of this machine.
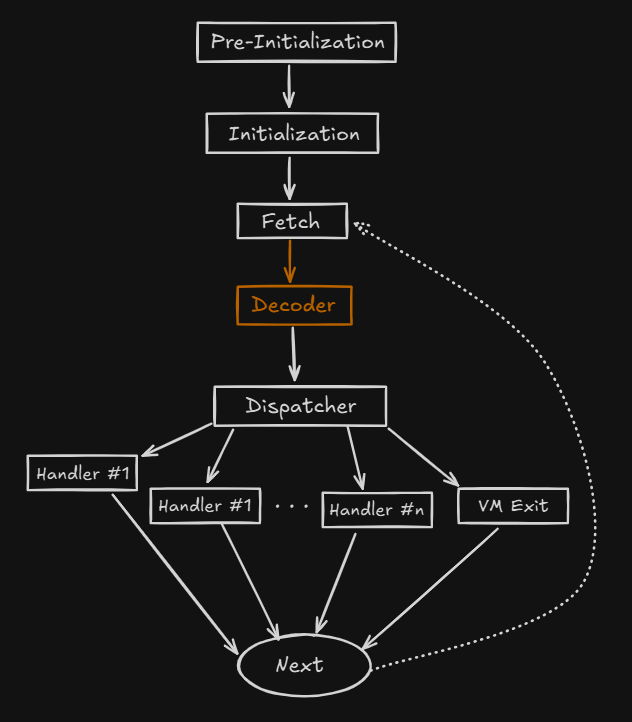
Analyzing the opcodes:
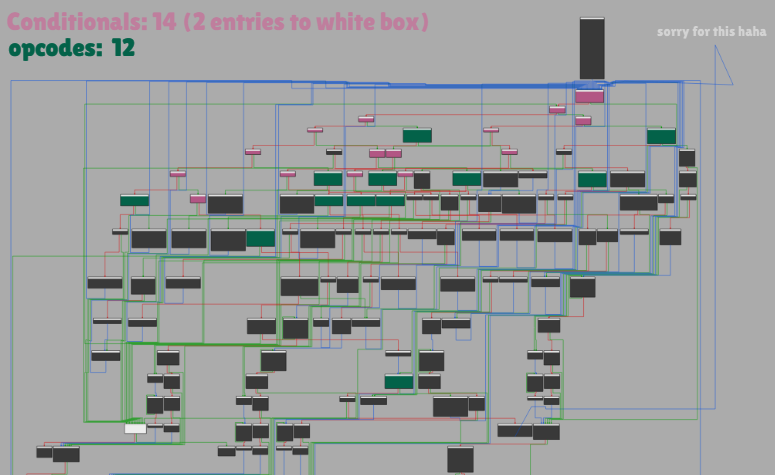
IDA Chart Legend:
Pink blocks: Conditional Handler
White block: Next instruction
Green blocks: Branch Handlers
Here a bit of spoiler but this is how looks the final IDA Chart, after all the reversing:

We easily locate 12 instructions, in our pseudo-code it looks something like this:
loc_1345:
i=rdx // rdx is a counter
vm_ip=i+1
*opcode = i
// Damos por hecho que si una accion es true, es un 0, es decir cuando se cumple jz la condiccion es true
if (opcode == 0x0AA) { loc_1470 }
else {
if (opcode > 0) { // START_loc_13B0
if (opcode == 0xD5) { loc_1810 }
else {
if (opcode <= 0) {
if (opcode == 0xB1) {
loc_1A50 // opcode == 0xB1
}
else {
if (opcode != 0xC3) { loc_1540 } // muchas llamadas
else { address_1504 } // opcode == 0xC3
}
}
else { // opcode > 0
if (opcode == 0xEF) { loc_1A90 }
else {
if (opcode != 0xF6) { loc_1540 } // muchas llamadas
else { address_1720 } //opcode == 0xF6
}
}
}
} // END_loc_13B0
else {
if (opcode == 0x5D) { loc_1B40 }
else {
if ( opcode > 0 ) { // START_loc_14B0
if (opcode == 0x7C) { loc_1B08 }
else {
if (opcode != 0x8B) { loc_1540 }
else { address_1720 }
}
} // END_loc_14B0
else {
if (opcode == 0x3E) { loc_1BA8 }
else {
if (opcode != 0x4A) {
if (opcode != 0x1E) { loc_1450 } // Possible op code
else { address_2101 }
}
else {
address_1379
}
}
}
}
}
}In a brief explanation, to detect the 12 opcodes I started in the dispacher, the first top pink square and start following the cmp and jumps instructions, at the moment we don’t analyze nothing, only we have scan the basics of the basics of the opcodes. In the pseudo-code we can obtain a small list of each opcode:
0x1E, 0x3E, 0x4A, 0x5D, 0x7C, 0x8B, 0xAA, 0xB1, 0xC3, 0xD5, 0xEF, 0xF6Also, its good to know that there will be 4 virtual registers that the opcodes are going to use, to in our pseudo-code we need to add it:
reg = [0x00,0x00,0x00,0x00]Anyways, I have forgotten to mention, this opcodes are getted for the first main function:
mov edx, 3B1Ah ; n
lea rsi, unk_3008 ; src 0x0000000000003008
xor r12d, r12dInside unk_3008 we find the source with some opcodes that coincides with the previous mention. To dump it, paste the following code in IDA python interpreter:
data = idaapi.get_bytes(0x0000000000003008, 0x3B1A)
with open("vmcode.txt", "w") as f:
f.write(data.hex())To start the solver check that all bytes extracted in vmcode.txt has the same lenght as the edx value, also verify the head and tail of both bytearrays.
file = open("vmcode.txt", 'r')
content = file.read()
vmcode = bytes.fromhex(content)
print(hex(len(vmcode)))Now that we have the bytearray, we can create the core of the solver.
file = open("vmcode.txt", 'r')
content = file.read()
vmcode = bytes.fromhex(content)
diss_vm = open("vm.asm", "w")
i = 0
reg = [0x00,0x00,0x00,0x00]
while i <len(vmcode)-1:
opcode = vmcode[i]
subOP = vmcode[i+1]
# ...
i += 1With this code, we enter into a loop to read all bytes from the bytearray, each opcode has his respective subcode or in other words; argument. If we apply the same logic of how to obatin the bytecodes with their arguments we can complete, for example, the bytecode: 0xf6:
if (opcode == 0xf6):
vm_ip = i + 2
eax = subOP # eax = byte ptr[rdx+1] = vmcode[i+1]
ecx = eax & 3
if (ecx == 0):
ecx = eax
eax = (eax >> 4) & 3
i += 5
ecx = (ecx >> 6) & 3
diss_vm.write(f"mov reg{eax}, {hex(ecx)}\n")
ecx = reg[ecx]
reg[eax] = ecx
elif (ecx == 2):
ecx = int.from_bytes(vmcode[i+2 : i+6], byteorder="little") # mov ecx, [rdx+2] -> read DWORD (4 bytes)
eax = (eax >> 4) & 3
i += 6
diss_vm.write(f"mov reg{eax}, {hex(ecx)}\n")
reg[eax] = ecx
else:
i += 1At the end of the day, it wass always the same, if we find some rdx address you know it will be: int.from_bytes(vmcode[], byteorder='little'), and byte ptr [rdx+1] being the subOP/vmcode[i+1]. After 4 hours of pure read assembly, we can create the following script:
file = open("vmcode.txt", 'r')
content = file.read()
vmcode = bytes.fromhex(content)
diss_vm = open("vm.asm", "w")
i = 0
reg = [0x00,0x00,0x00,0x00]
while i < len(vmcode)-1:
opcode = vmcode[i]
subOP = vmcode[i+1]
if (opcode == 0xf6):
vm_ip = i + 2
eax = subOP # eax = byte ptr[rdx+1] = vmcode[i+1]
ecx = eax & 3
if (ecx == 0):
ecx = eax
eax = (eax >> 4) & 3
i += 5
ecx = (ecx >> 6) & 3
ecx = reg[ecx]
diss_vm.write(f"mov reg{eax}, {hex(ecx)}\n")
reg[eax] = ecx
elif (ecx == 2):
ecx = int.from_bytes(vmcode[i+2 : i+6], byteorder="little") # mov ecx, [rdx+2] -> read DWORD (4 bytes)
eax = (eax >> 4) & 3
i += 6
diss_vm.write(f"mov reg{eax}, {hex(ecx)}\n")
reg[eax] = ecx
else:
i += 1
elif (opcode == 0xaa):
vm_ip = i + 2
eax = subOP
ecx = eax & 3
if (ecx == 0):
ecx = eax
eax = (eax >> 6) & 3
ecx = (ecx >> 4) & 3
i += 6
esi = reg[ecx]
diss_vm.write(f"sub reg{ecx}, {hex(reg[eax])}\n")
esi = esi - reg[eax]
diss_vm.write(f"mov reg{ecx}, {hex(esi)}\n")
reg[ecx] = esi
elif (ecx == 2):
eax = (eax >> 4) & 3
i += 8
ecx = reg[eax]
diss_vm.write(f"sub reg{eax}, {hex(int.from_bytes(vmcode[i-6 : i-2], byteorder='little'))}\n")
ecx = ecx - int.from_bytes(vmcode[i-6 : i-2], byteorder='little')
diss_vm.write(f"mov reg{eax}, {hex(ecx)}\n")
reg[eax] = ecx
else:
i += 1
elif (opcode == 0xef):
vm_ip = i + 2
eax = ecx = subOP
ecx = ecx & 3
if (ecx == 0):
edx = eax
eax = (eax >> 4) & 3
edx = (edx >> 6)
fd = reg[eax]
buf = hex(edx)
n = 1
diss_vm.write(f"write({fd}, {buff}, {n})\n")
i = vm_ip
elif (ecx == 1):
eax = eax >> 6
fd = vmcode[i+2] # 1
n = 1
buff = hex(eax)
diss_vm.write(f"write({fd},{buff},{n})\n")
i = vm_ip + 2
elif (ecx == 2):
eax = (eax >> 4) & 3
n = 1
fd = reg[eax]
buff = vmcode[i+2]
diss_vm.write(f"write({eax},{hex(buff)},{n})\n")
i = vm_ip + 1
elif (ecx == 3):
fd = vmcode[i+3]
n = 1
buff = vmcode[i+2]
diss_vm.write(f"write({fd},{hex(buff)}, {n})\n")
i = vm_ip + 3
else:
i += 1
elif (opcode == 0x4a):
vm_ip = i + 2
eax = subOP
esi = eax & 3
if (esi == 0):
rdx = eax
eax = (eax >> 6) & 3
rdx = (rdx >> 4) & 3
eax = reg[eax]
diss_vm.write(f"add reg{rdx}, {hex(eax)}\n")
reg[rdx] = reg[rdx] + eax
i = vm_ip
elif (esi == 2):
eax = (eax >> 4) & 3
ecx = int.from_bytes(vmcode[i+2 : i+6], byteorder='little')
i += 7
diss_vm.write(f"add reg{eax}, {hex(ecx)}\n")
reg[eax] = ecx
else: # elif (esi == 1)
i += 1
elif (opcode == 0x8b):
vm_ip = i + 2
eax = subOP
ecx = eax & 3
if (ecx == 0):
ecx = eax
eax = (eax >> 6) & 3
ecx = (ecx >> 4) & 3
i += 3
eax = reg[eax]
diss_vm.write(f"xor reg{ecx}, {hex(eax)}\n")
reg[ecx] = reg[ecx] ^ eax
elif (opcode == 2):
eax = (eax >> 4) & 3
i += 6
ecx = reg[eax]
diss_vm.write(f"xor {hex(eax)}, {hex(int.from_bytes(vmcode[i-4 : i], byteorder='little'))}\n")
ecx = ecx ^ int.from_bytes(vmcode[i-4 : i], byteorder='little')
#diss_vm.write(f"mov reg{eax}, {hex(ecx)}\n")
reg[eax] = ecx
else:
i+=1
elif (opcode == 0x5d):
vm_ip = i + 2
eax = subOP
ecx = eax & 3
if (ecx == 0):
ecx = eax
i += 3
vm_ip = i
ecx = (ecx >> 6) & 3
ebp = reg[ecx]
eax = (eax >> 4) & 3
fd = 0 #stdin
n = ebp
buf = eax
diss_vm.write(f"read({fd},&{buf},{n})\n")
i = vm_ip
elif (ecx == 2):
ebp = int.from_bytes(vmcode[i+2: i+4], byteorder="little")
i += 8
vm_ip = i
eax = (eax >> 4) & 3
fd = 0 #stdin
n = ebp
buf = eax
diss_vm.write(f"read({fd},&{buf},{n})\n")
i = vm_ip
else:
i += 1
elif (opcode == 0x7c):
vm_ip = i + 2
eax = subOP
ecx = eax & 3
if (ecx == 0):
esi = eax
eax = (eax >> 6) & 3
i += 4
esi = (esi >> 4) & 3
ecx = reg[eax]
diss_vm.write(f"shl reg{esi}, {hex(ecx)}\n")
reg[esi] <<= ecx
elif (ecx == 2):
eax = (eax >> 4) & 3
ecx = vmcode[i+2]
i += 7
diss_vm.write(f"shl reg{eax}, {hex(ecx)}\n")
reg[eax] <<= ecx
else:
i += 1
elif (opcode == 0xb1):
vm_ip = i + 2
eax = subOP
ecx = eax & 3
if (ecx == 0):
edx = eax
eax = (eax >> 6) & 3
i+=4
edx = (edx >> 4) & 3
ecx = reg[eax]
diss_vm.write(f"shl reg{edx}, {hex(ecx)}\n")
reg[edx] <<= ecx
i = vm_ip
elif (ecx == 2):
eax = (eax >> 4) & 3
ecx = vmcode[i+2]
i+=6
diss_vm.write(f"shr reg{eax}, {hex(ecx)}\n")
reg[eax] >>= ecx
else:
i += 1
elif (opcode == 0xd5):
vm_ip = i + 2
eax = subOP
ecx = eax & 3
if (ecx == 0):
i+=4
elif (ecx == 1):
i+=3
elif (ecx == 2):
r8d = int.from_bytes(vmcode[i+2 : i+4], byteorder='little')
eax = ((~r8d) & 7) + 1
diss_vm.write(f"rol {hex(eax)}\n")
i+=7
elif (ecx == 3):
r8d = int.from_bytes(vmcode[i+2 : i+4], byteorder='little')
eax = ((~r8d) & 7) + 1
diss_vm.write(f"ror {hex(eax)}\n")
i+=9
else:
i+=1
elif (opcode == 0xc3):
vm_ip = i + 2
eax = subOP
ecx = eax & 3
if (ecx == 0):
ecx = eax
eax = (eax >> 6) & 3
ecx = (eax >> 4) & 3
eax = reg[eax]
diss_vm.write(f"cmp reg{ecx}, {hex(eax)}\n")
r12d = 1
i += 4
elif (ecx == 2):
eax = (eax >> 4) & 3
edi = int.from_bytes(vmcode[i+2 : i+6], byteorder='little')
diss_vm.write(f"cmp reg{eax}, {hex(edi)}\n")
i += 7
else:
i +=1
elif (opcode == 0x1e):
vm_ip = i + 2
eax = subOP
eax = eax & 3
diss_vm.write(f"swap reg, reg1\n")
if (opcode == 0):
ecx += 3
elif (opcode == 1):
i += 8
elif (eax == 2):
i += 9
elif (eax == 3):
i += 10
else:
i += 1
elif (opcode == 0x3e):
vm_ip = i + 2
eax = subOP
ecx = eax & 3
if (ecx == 0):
ecx = eax
eax = (eax >> 6) & 3
i += 4
ecx = (ecx >> 4) & 3
diss_vm.write(f"mov reg{eax}, {hex(eax)}\n")
eax = reg[eax]
elif (ecx == 2):
eax = (eax >> 4) & 3
i += 7
ecx = reg[eax]
diss_vm.write(f"mov reg{eax}, {hex(ecx)}\n")
reg[eax] = ecx
else:
i += 1
else:
i += 1Now inside vm.asm, the pure vm is found. By passing it to chatgpt (I dont know that much of assembly), it will tell us is a Tiny Encryption Algorithm. In this algorithm use the following encryption function:
#include <stdint.h>
void encrypt (uint32_t v[2], const uint32_t k[4]) {
uint32_t v0=v[0], v1=v[1], sum=0, i; /* set up */
uint32_t delta=0x9E3779B9; /* a key schedule constant */
uint32_t k0=k[0], k1=k[1], k2=k[2], k3=k[3]; /* cache key */
for (i=0; i<32; i++) { /* basic cycle start */
sum += delta;
v0 += ((v1<<4) + k0) ^ (v1 + sum) ^ ((v1>>5) + k1);
v1 += ((v0<<4) + k2) ^ (v0 + sum) ^ ((v0>>5) + k3);
} /* end cycle */
v[0]=v0; v[1]=v1;
}To find correctly the key and the block sizes, they have to coincide with the following lenghts:
- Key sizes 128 bits
- Block sizes 64 bits
For the delta value I choose the bytes that more repeat in all the script, because is the unique constant inside the for-loop, being the value: 0xe09ffbb1, showing a total of 64 times as:
add regN, 0xe09ffbb1To start the script we obtain the following base-function:
void decrypt (uint32_t v[2], const uint32_t k[4]) {
uint32_t v0=v[0], v1=v[1], sum=0xC6EF3720, i; /* set up; sum is (delta << 5) & 0xFFFFFFFF */
uint32_t delta=0x9E3779B9; /* a key schedule constant */
uint32_t k0=k[0], k1=k[1], k2=k[2], k3=k[3]; /* cache key */
for (i=0; i<32; i++) { /* basic cycle start */
v1 -= ((v0<<4) + k2) ^ (v0 + sum) ^ ((v0>>5) + k3);
v0 -= ((v1<<4) + k0) ^ (v1 + sum) ^ ((v1>>5) + k1);
sum -= delta;
} /* end cycle */
v[0]=v0; v[1]=v1;
}Knowing delta value, we can obtain also the sum one
# sum = (delta << 5) & 0xFFFFFFFF
>>> delta = 0xe09ffbb1
>>> sum = (delta << 5) & 0xFFFFFFFF
>>> hex(sum)
'0x13ff7620'Thus, our function is completed, now we have to find the key and cipher-text.
void decrypt (uint32_t v[2], const uint32_t k[4]) {
uint32_t v0=v[0], v1=v[1], sum=0x13ff7620, i; /* set up; sum is (delta << 5) & 0xFFFFFFFF */
uint32_t delta=0xe09ffbb1; /* a key schedule constant */
uint32_t k0=k[0], k1=k[1], k2=k[2], k3=k[3]; /* cache key */
for (i=0; i<32; i++) { /* basic cycle start */
v1 -= ((v0<<4) + k2) ^ (v0 + sum) ^ ((v0>>5) + k3);
v0 -= ((v1<<4) + k0) ^ (v1 + sum) ^ ((v1>>5) + k1);
sum -= delta;
} /* end cycle */
v[0]=v0; v[1]=v1;
}To obtain the key value:
uint32_t k[4] = {0x80b86e21, 0xa268295d, 0xf171f22d, 0x28a13c94};We have to focus in the read function, as reg2 and reg3 gets prepared for the read input we obtain that two values,
read(0,&0,4)
read(0,&1,4)
mov reg2, 0x0
mov reg3, 0x0
shl reg2, 0x4
shr reg3, 0x5
add reg2, 0x80b86e21
add reg3, 0xa268295dand the next two the same way:
read(0,&2,63140)
shr reg1, 0x5
shl reg0, 0x4
add reg0, 0xf171f22d
add reg1, 0x28a13c94For cipher value as it is comparing it to check if the flag is correct, we have to find the cmp instructions followed from a write instruction, for the first part of the flag:
write(0,0x6a,1)
ror 0x1
cmp reg2, 0xfb987633
cmp reg3, 0xa2500488uint32_t v[2] = {0xfb987633, 0xa2500488};And for the second part, I found it because the registers were the same hahaha followed from the ror 0x1:
ror 0x1
cmp reg2, 0x6ce7082d
cmp reg3, 0xc03a492fuint32_t v[2] = {0x6ce7082d, 0xc03a492f};And after modifying a bit of the logic of the decryption function, we have the final solver;
#include <cstdio>
#include <cstdint>
void decrypt (uint32_t v[2], const uint32_t k[4]) {
uint32_t v0=v[0], v1=v[1], sum=0x13ff7620, i; /* set up; sum is (delta << 5) & 0xFFFFFFFF */
uint32_t delta=0xe09ffbb1; /* a key schedule constant */
uint32_t k0=k[0], k1=k[1], k2=k[2], k3=k[3]; /* cache key */
for (i=0; i<32; i++) { /* basic cycle start */
if (i==9)
v1 -= ((v0<<2) + k2) ^ (v0 + sum) ^ ((v0>>3) + k3);
else
v1 -= ((v0<<4) + k2) ^ (v0 + sum) ^ ((v0>>5) + k3);
v0 -= ((v1<<4) + k0) ^ (v1 + sum) ^ ((v1>>5) + k1);
sum -= delta;
} /* end cycle */
v[0]=v0; v[1]=v1;
}
int main() {
uint32_t k[4] = {0x80b86e21, 0xa268295d, 0xf171f22d, 0x28a13c94};
uint32_t v[2] = {0xfb987633, 0xa2500488};
decrypt(v,k);
printf("%s\n",v);
v[0] = 0x6ce7082d;
v[1] = 0xc03a492f;
decrypt(v,k);
printf("%s",v);
return 0;
}$> ./main
xNVa2_N0!n��])h�-�q�<�(
7_t3aAlg!n��])h�-�q�<�(%
$> ./KataVM_L1
.-------------------------.
| Towel's KataVM: Level 1 |
'-------------------------'
>> xNVa2_N07_t3aAlg
[+] Correct!Congrats for solving the challenge, and thanks you for your time and reading the blog :) God bless you.